
Data Shortage and Efficiency, Improving Model Calibration Estimation
PandaScore Research Insights #9



Will we come short of data?
What it is about: In 2022, researchers from Epoch, an organization focusing on forecasting transformative AI development, published a paper examining the sustainability of the current growth in dataset size. They investigated computer vision and language tasks.
How it works: To determine when we will run out of available data, the study forecasts the stocks of available data and dataset sizes.
Most of the data is user-generated (e.g., on social media platforms). Therefore, the available stock of data can be forecasted based on world population growth, internet penetration rate, and the amount of data produced by a single user (assumed to be constant). That being said, user-generated data might not be of high quality, which is better for training models (e.g., Twitter data vs. scientific publications). This kind of data is expected to grow slower, at the rate of world economic growth.
In projecting the growth of dataset sizes used to train the models, they propose starting from the estimated growth of compute power and then using scaling laws that predict the optimal dataset size for a given compute budget.
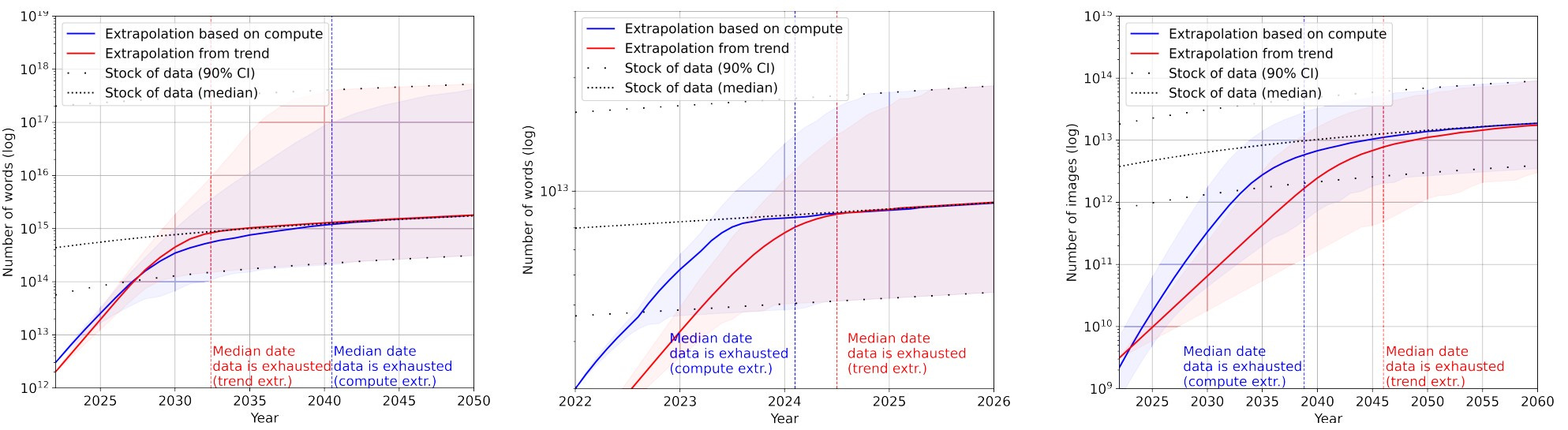
What they found out: What is the growth of dataset sizes in relation to the available stock?
Language datasets have exponentially grown in recent years (50% per year), while the stock of data is expected to grow by 7% annually. Currently, the stock of available data is 1.5 to 4.5 orders of magnitude larger than the largest dataset (FLAN with 1.82e12 data). However, the stock of high-quality data is less than 1 order of magnitude larger. This suggests a potential shortage of language data between 2023 and 2027.
Vision dataset sizes grow at a faster rate (18%-31% per year) than the available data stock (8% per year). The current stock of vision data is 3 to 4 orders of magnitude larger than the largest dataset (JFT-3B with ~3B data). It is likely that we will face a shortage of vision data between 2030 and 2070.
Why it matters: While some researchers try to leverage small amounts of data when training models (e.g., zero/few-shot training), adding more data and making models bigger yields better performance nowadays. But how long can this trend continue? Collecting and curating datasets has become more and more expensive as data is harder to find, especially high-quality data.
Our takeaways: Even if it might not be applicable to all domains, synthesizing artificial data can already be a valuable way to make datasets bigger. Not only can datasets be made larger, but also richer as rare or hypothetical samples can be generated. At PandaScore, particularly when working on detecting elements in video streams, we make use of artificial sample synthesis to improve the models.
Beating power laws with dataset pruning
What it is about: This work from Meta AI focuses on improving the ratio between the amount of data needed during training and the performance of the model. It was published in NeurIPS 2022.
How it works: The idea is to prune the dataset to retain only the most useful examples. By feeding the model with only these useful examples, the dependency between the amount of training data needed and the model's performance is reduced.
A new metric is proposed to prune the dataset, based on computing a difficulty score for each sample. A difficult sample is one for which the model struggles to find the correct answer. This metric is calculated by training multiple small student models intentionally not perfectly trained. A sample that is not well classified by these small models would receive a higher ranking on the difficulty scale. Another contribution of this work is to identify when it is preferable to use easy examples versus hard ones.
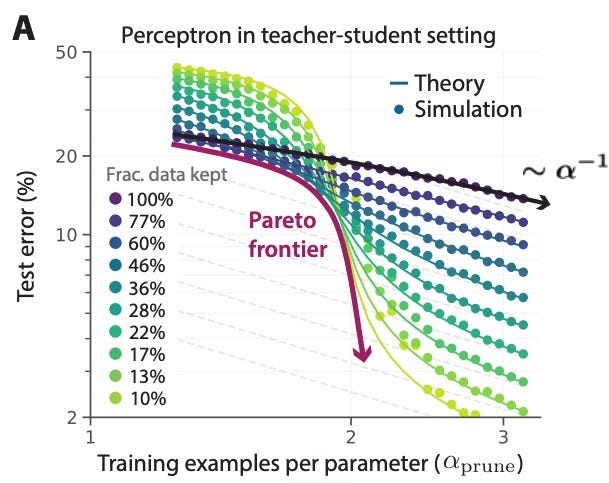
Results: In their analysis of which type of examples are best for training, they found that it is generally better to feed the model with difficult examples. However, in the context of having a low number of data points, feeding the model with easy examples is better. They compared their pruning strategy with a state-of-the-art memorization strategy, which is based on evaluating the model's capability to memorize (and not make errors) the example during training. They obtained comparable results even though their method is self-supervised.
What they found out: They discovered that it is possible to break the power law scaling with proper data pruning.
Why it matters: The cost of collecting and labeling data has always been a limiting factor for models, which constantly require more data. Having a statement that suggests not needing 10 times more data to achieve marginal improvements in model performance should be taken seriously.
Our takeaways: Even though esports data can be collected more easily than in traditional sports, it is still important to consider the quality of the collected data. Doing so would reduce unnecessary costs associated with collecting and labeling data that is not useful.
Estimating the Expected Calibration Error
What it is about: This paper from 2021 by R&D engineers from the consulting firm Euranova discusses the estimation of a classifier's ability to capture uncertainty.
How it works: A probabilistic model is considered "well calibrated" if it effectively captures uncertainty, meaning its outputs accurately reflect the true probabilities for each class (for a more detailed introduction to the concept of calibration, see this past blogpost). After providing a detailed introduction to the concept of calibration, the authors focus on comparing different evaluators of calibration:
ECE legacy: The most common evaluator, which calculates a weighted mean of the absolute differences between accuracy and confidence on the reliability diagram. Binning is done uniformly, such as with 4 bins:
[0, 0.25), [0.25, 0.5), [0.5, 0.75), [0.75, 1].ECE adaptive: Similar to ECE legacy, but with adaptive binning where each bin contains the same number of samples.
ECE convex: Similar to ECE legacy, but with the ability for one sample to contribute to 2 bins. This is the first contribution of the paper.
ECE adaptive convex: A combination of ECE adaptive and ECE convex.
ECE kde: A continuous version of ECE legacy that uses kernel density estimations (Local Calibration Error) and does not require any hyperparameter choices. This is the second contribution of the paper. Unlike the first four estimators of the ECE, ECE kde does not require determining hyperparameters such as the number of bins before computing its value.
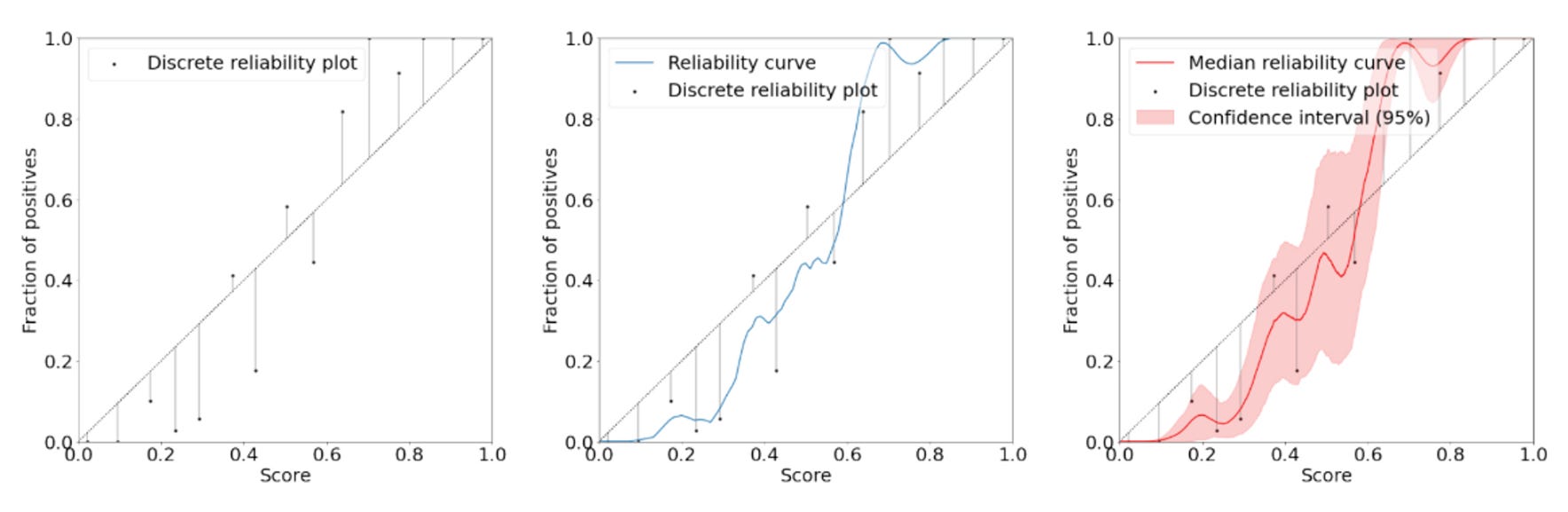
Results: The newly proposed estimator demonstrated better performance than the legacy estimators of calibration in the confidence setting, where calibration is evaluated only for the class with the highest score. However, the results were less clear in the class-wise setting, where calibration is evaluated for all classes, including those with very low scores.
Our takeaways: Understanding and evaluating model calibration is crucial for an esports odds company like PandaScore, as it directly impacts the reliability and accuracy of predicted probabilities for match outcomes. It leads to better odds for customers, ultimately enhancing the betting experience and fostering transparency and fairness in the industry.
Additionally, by investigating model calibration, this research paper contributes to the broader field of machine learning evaluation and helps in the development of better calibration techniques, benefiting various domains beyond esports betting.
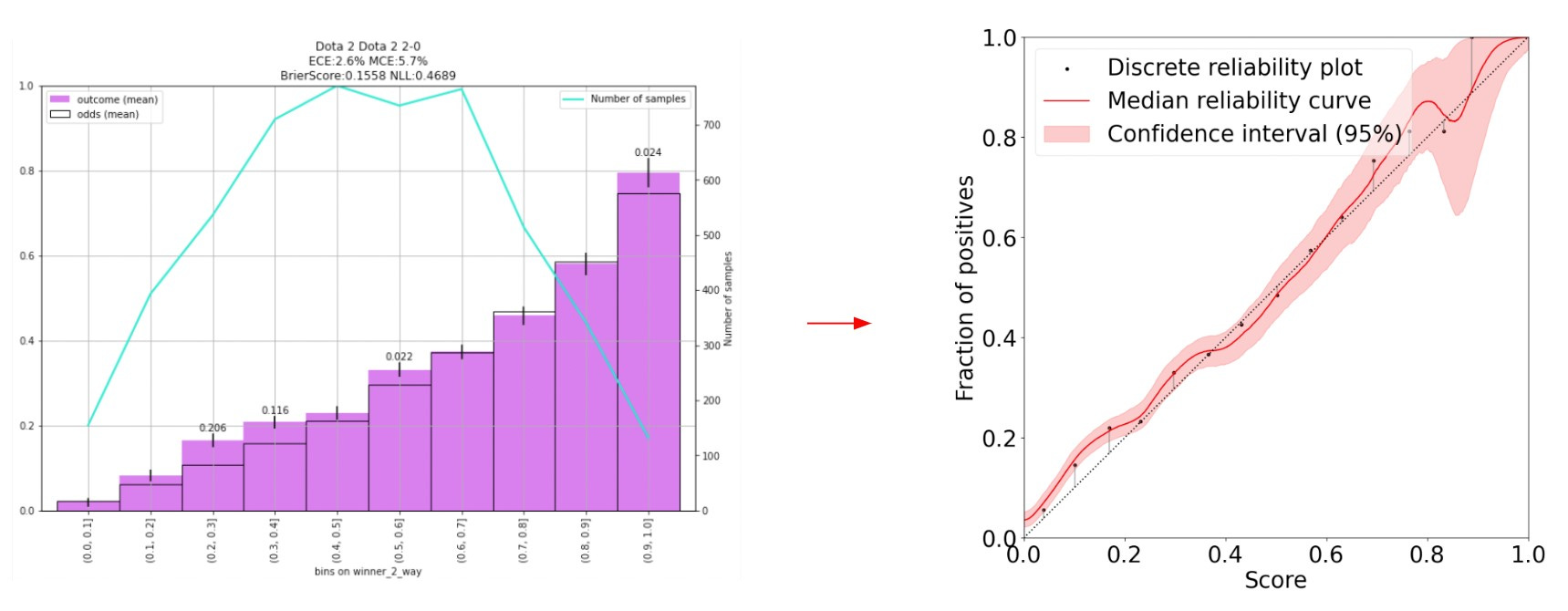
We would also like to express our gratitude to the authors for open-sourcing their code, which enabled us to experiment with the new calibration estimator on our own data, see below.
 | A guest post by
|