
Rating players performance, bias in calibration, and conditional GANs
PandaScore Research Insights #2



Soccer Player Rating with Machine Learning
What it is about: In 2019, researchers from Italy jointly published with a scouting company a paper describing a framework that evaluates and rates the performance of soccer players. They use the performance rating of players to rank players based on their role.
How it works: First, they compute the rating of a given player in a given match as the linear combination of features describing its actions during the match. Features comprise the number of successful passes, duels, fouls, and more. The weights are derived from a linear Support Vector Classifier (SVC). It has been trained on the aggregated features of the team to predict the outcome of the match. In parallel, a k-means model computes the player role as the region it played in during the match. Finally, they rank players by role by ordering them using their ratings.

Results: The SVC model was able to predict the outcome of a match with a 82% accuracy (compared to a naïve classifier predicting always non-victory that achieves 62%). As for the rating of the players and the rankings, they reach 74% agreement with experts when they are unanimous ranking a player above another.

Why it matters: Commonly used metrics in assessing the player performance during a match have several issues. They can be quite simplistic (e.g., number of passes) or can be biased toward a certain role or play style (e.g., number of shots). Data-driven approaches could be used to analyze and evaluate better the performance of players. A lot of different actors in the industry could benefit from these approaches, from coaches, to scouts and medias.
Our takeaways: We believe that their approach, using the game outcome as a proxy to the player performance, is relevant. However, one issue still remains: how do you account for the teammates performance? For instance, the very good performance of a player could inflate his teammates’. This could be even more problematic for other sports and esports where the number of players is fewer. Indeed, the less a game has players, the higher the impact of the individual player on the outcome, and therefore on its teammates’ performance.
Mitigating Bias in Calibration Error Estimation
What it is about: This paper (Google Research, 2022) studies the statistical bias of common estimators of the True Calibration Error.

How it works: True Calibration Error (TCE) measures the difference between the predicted confidence of a model and the true likelihood of being correct. In simple words, calibration methods assess whether the confidence of a model in its predictions is well distributed. For example, among the predictions with 70% confidence for a given class, around 70% of them should be correct. This is the methodology they propose to compute the bias of a given TCE estimator:
For a given model (such as a trained ResNet on CIFAR-10), Generalized Linear Models and beta distributions are fitted to respectively the distribution of scores (output of the model) and the reliability curve.
TCE is computed as the ECE of samples from the fitted distribution.
Bias is computed as the difference between the ECE of the chosen estimator and the TCE.
What they found out: Estimating the calibration of a model using equal mass binning gives a better approximation of the TCE than using equal width binning, widely used in research on calibration. They also showed that for each sample size on which calibration is estimated, there exists an optimal number of bins to minimize the bias. As expected intuitively, this number grows with the size of the sample set. Finally, the authors suggest a new promising estimator of the calibration error.
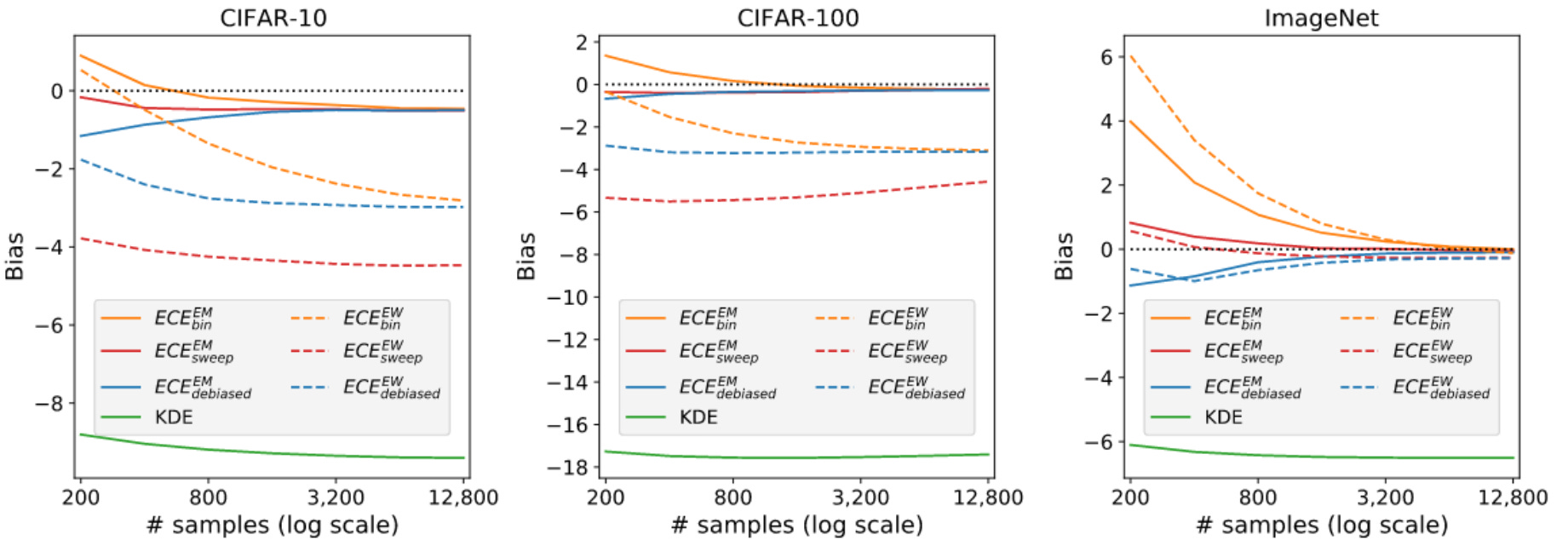
Why it matters: For many use cases of Machine Learning, it is critical for a model to be well calibrated (e.g., self-driving cars, medical diagnosis, betting). Gue et al. showed in 2017 that, while modern deep learning models have a much better accuracy than before, their calibration is worse. Since then, many researchers have worked on recalibration techniques.
Our takeaways: In betting, we are looking for perfectly calibrated models. There are many insights in this paper that can be directly used at PandaScore in order to assess the quality of our models. Finally, we strongly appreciate research work trying to find better ways to evaluate calibration since using different estimators can lead to different recalibration method!
Avoiding mode collapse with conditional GANs
What it is about: This paper, published in ICLR and written in 2018 by researchers from Ritsumeikan University, proposes modification to the training framework of conditional GAN models (cGAN) to better tackle the mode collapse issue.
How it works: In cGAN (paper), the extra information (can be a label corresponding to one class of the dataset for instance) is preprocessed (one-hot or embedding) and concatenated to the seed / latent representation. The extra information is then added to the output of the generative process and fed to the discriminator. The discriminator is responsible of the good conditional generation results. GANs generally suffers from mode collapse and cGAN is no exception. The generator fails to output data samples that are as diverse as the distribution of the real-world data. To tackle this issue, the authors propose to change the way the extra information is added. In practice, it helps the model at converging to an optimal solution more steadily.

Why it matters: GANs have revolutionized the way we generate synthetic data. However, they are known to show instability during training. This paper provides ways to make this generative process more robust while producing better quality objects.
Our takeaways: We liked the general idea of conditioning the output of a model. When computing odds about esports game events, it could be used to add knowledge from domain experts to the model. It could be particularily useful to adapt the odds during the game by controlling more precisely the different modes.
 | A guest post by
|