
Synthetic Data Generation, Netflix Data Processing Pipeline, Adding Information Retrieval to LLMs
PandaScore Research Insights #16



Generating Data with Diffusion and Flow-based Gradient-Boosted Trees
What it is about: This paper, published in early 2024 by researchers from the Samsung AI Lab, presents a novel approach to generating synthetic mixed-type tabular data that mirrors real-world data distributions.
How it works: This method combines Gradient-Boosted Trees (GBTs) with advanced data generation techniques called diffusion models and conditional flow matching.
Diffusion Models: These models start with noisy data and gradually remove the noise to create realistic data, guided by learned patterns.
Conditional Flow Matching: This approach learns how to transform random data points into realistic ones through a series of steps.
The key idea is to use XGBoost (a type of GBT) to estimate the necessary patterns or transformations for generating data. The process involves several steps:
Duplication and Adding Noise: The original dataset is copied multiple times, and different amounts of random noise are added to each copy.
Training Models for Each Noise Level: Separate XGBoost models are trained to handle each level of noise, allowing the process to run efficiently on CPUs.
Creating Smooth Transitions: The noisy datasets are smoothly transitioned across different time steps using interpolation, ensuring a stable data generation process.
Generating and Completing Data: To create new data, the method gradually removes noise from the data. For filling in missing values, it uses the REPAINT algorithm to replace missing data step by step.

Results: The method was empirically evaluated on 27 real-world datasets for both data generation and imputation tasks. Key findings include:
Data Generation: The method achieved superior performance in generating realistic synthetic data, often outperforming other deep-learning-based methods across various metrics.
Data Imputation: It was competitive with leading imputation methods, showing high diversity in imputations and good performance metrics.
Efficiency: The method can be trained using CPUs, making it more accessible compared to GPU-dependent deep learning models.
Why it matters: This method offers a practical solution for handling tabular data, addressing challenges in generating realistic synthetic datasets and imputing missing values. Data generation is particularly useful in scenarios where data volume is limited. Additionally, the ability to effectively train on CPUs makes this approach accessible to a wider range of domains.
Our takeaways: While generative AI has seen increased interest in unstructured data like images and video, this paper introduces a novel way to achieve similar generative capabilities for tabular data. The methods presented also have the added advantage of being easier to train and manage, as the XGBoost models used can be handled entirely on CPUs.
Psyberg: An Incremental Data Processing Framework at Netlflix
What it is about: In November 2023, Netflix published articles introducing Psyberg. Later that year, they presented Psyberg at their Data Engineering Tech Talk. Psyberg is Netflix's framework for incremental data processing. In other words, Psyberg is used to compute batches of data at a regular intervals.
How it works: Psyberg relies on metadata, using Iceberg to track snapshots and partitions of processed data. A watermark is a marker that indicates the latest point in the data stream that has been processed, ensuring no data is missed or duplicated. Psyberg maintains two metadata tables:
High Watermark Table: Records the current and previous watermark timestamps.
Session Metadata Table: Stores information about each pipeline run.
Psyberg operates in two modes: stateless and stateful. Stateless mode is designed for events that depend only on themselves. In this case, late or missing data can be appended to the target. Stateful mode is useful for events that depend on previous events. Handling of late or missing stateful data involves overwriting the target and recomputing.
Regardless of the modes, Psyberg can be divided into three steps:
Psyberg Init: Identify the range of data to process, which mode to use based on metadata from the previous run.
Write-Audit-Publish process: Compute all events, perform checks, and publish data.
Psyberg Commit: Save the new high watermark.
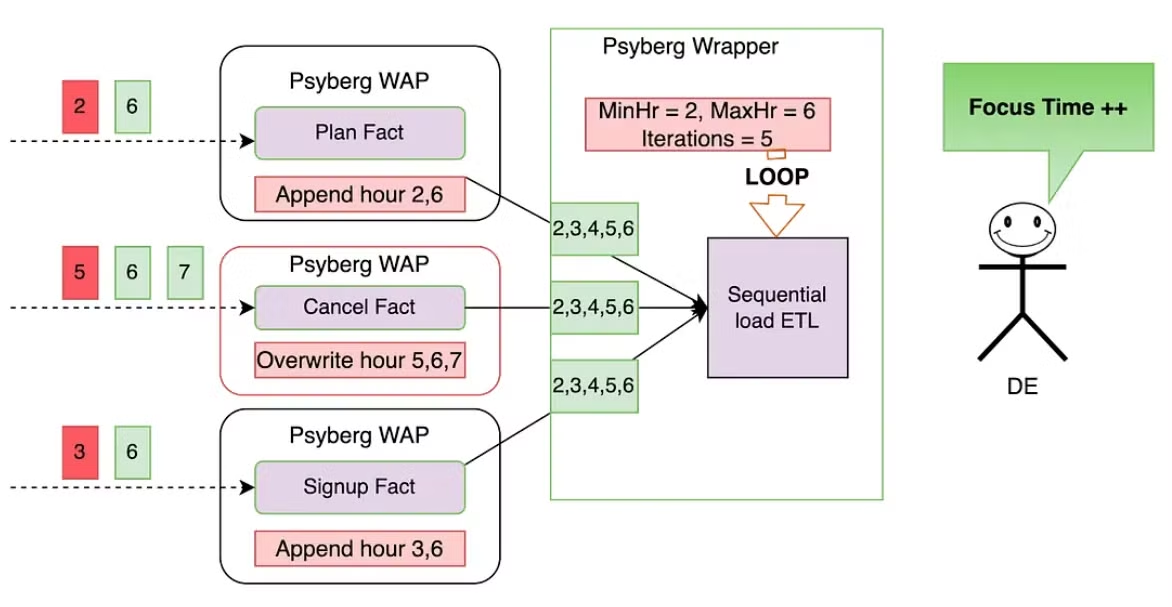
Why it matters: It is critical for data to be up-to-date and for each run to be on time. Data computed incrementally helps stakeholders make decisions. Decisions cannot be made correctly if data is not fresh. When data arrives late, Psyberg can catch up by processing the latest data updates. Additionally, Psyberg helps data engineers easily recover from data incidents by reducing the number of manual operations required.
Our takeaways: As we strive to make data available for analysis as early as possible, these articles were interesting to explore how large-scale companies handle the challenges of high-rate incremental processing.
RA-DIT: Adding Information Retrieval Capabilities to LLMs
What it is about: Researchers at Meta published in May a paper introducing Retrieval-Augmented Dual Instruction Tuning (RA-DIT), a lightweight method to add external information retrieval capabilities to existing Large Language Models (LLMs).
How it works: Their architecture uses two modules: the retriever and the LLM.
Retriever: The retriever returns the most relevant chunks of text for a given question. These chunks are extracted from a large pool of documents. Based on an LLM, the matching captures deep semantic meaning between the query and the chunks.
LLM: Each chunk output by the retriever is prepended individually to the model prompts. This creates multiple augmented prompts from the same initial prompt. All the answers are then combined to produce the final answer.

Both models are individually fine-tuned to improve their performance when used in tandem. The retriever is fine-tuned by maximizing the probability of the output chunks being useful to the LLM. The LLM is fine-tuned with the added chunks so that it learns to use them more effectively, while also learning to discard irrelevant ones.
Results: In their experiments, the researchers used the BERT-based dense retriever DRAGON* and the open-source LLM LLAMA (1st version). The resulting model achieves better performance on knowledge-intensive tasks (e.g., Natural Questions, TriviaQA) compared to both an LLM without a retriever and a non-fine-tuned LLM with a retriever. Additionally, they demonstrate through common-sense reasoning tasks that the model still performs well when the retriever is not needed. This shows that the fine-tuning approach did not compromise the parametric knowledge and reasoning capabilities originally possessed by the model.
Why it matters: One of the main challenges of LLMs is that they don't have up-to-date knowledge. While augmenting them with retrieval capabilities has shown to alleviate this issue, it remains challenging. Most common approaches either need to modify the LLM pretraining, which is expensive, or use external data stores, leading to suboptimal performance.
Our takeaways: Augmenting LLMs with private data sources is becoming increasingly important for companies. However, the most common technique, Retrieval-Augmented Generation (RAG), is known to be quite tedious to work with as the LLM has not been trained to use the retrieved content well. This paper proposes a solution that should be more easily applied by businesses to efficiently make use of in-house LLMs, potentially opening up new possibilities for leveraging and customizing language models in various business contexts.
 | A guest post by
|
 | A guest post by
|