
Promptbreeder, Sequence Modeling with SSMs, Reverse Favorite-Longshot Bias in Esports Betting
PandaScore Research Insights #15




Promptbreeder
What it is about: Researchers from DeepMind introduce Promptbreeder, a system designed to optimize and evolve prompts for large language models. The study, conducted in 2023, focuses on improving prompt efficiency and effectiveness.
How it works: A group of pairs of task-prompts (P) and mutation-prompts (M) is selected. Task-prompts instruct the LLM on how to perform a task (e.g., "Craft a detailed response to appear knowledgeable"), while mutation-prompts guide how questions are modified (e.g., "Alter this instruction for a more entertaining tone"). The accuracy of these pairs is assessed on a training dataset. The most effective pairs undergo mutation using different operators, and the resulting mutants replace the less effective pairs from the original selection. This genetic process is repeated (typically for 20-30 generations) which leads to better and better prompts for a given family of tasks.
Results: Promptbreeder outperforms all competitor strategies (Chain-of-Thought, Program-of-Thought, OPRO, etc.) on most datasets. The datasets cover various families of tasks such as arithmetic, answering sequences of inter-related questions on HTML tables, and high quality linguistically diverse grade school math word problems.
Why it matters: Effective prompt optimization is essential for unlocking the full capabilities of large language models, influencing their performance across a wide range of applications and industries reliant on AI-driven solutions.
Our takeaways: We particularly appreciated this paper because it leverages two key concepts:
Prefixing a prompt with context often yields much better results, as shown in the past by previous research on prompt engineering.
LLMs are good at generating variations of inputs. We found it particularly interesting that in this paper, researchers leverage this ability by using a genetic algorithm to find the best prompts for a given task. The self-referential aspect of the paper (using the same LLM for both ****tasks and mutations) makes it particularly elegant.
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
What it is about: In late 2023, researchers from Carnegie Mellon and Princeton University proposed an evolution of State Space Models (SSMs) called Mamba to address Transformers’ computational inefficiency on long sequences.
Background: SSM are sequence-to-sequence models inspired by State Spaces (Kalman, 1960). The model variables, the states, change over time depending only on their current values. This means the future state of the system depends only on its current state, not on its history.
The most powerful feature of a SSM is that it can be expressed in 3 different ways, from which we can switch between depending on the use-case. For instance, we can use the Convolutional form during training and the Recurrent form during inference to take advantage of both forms.
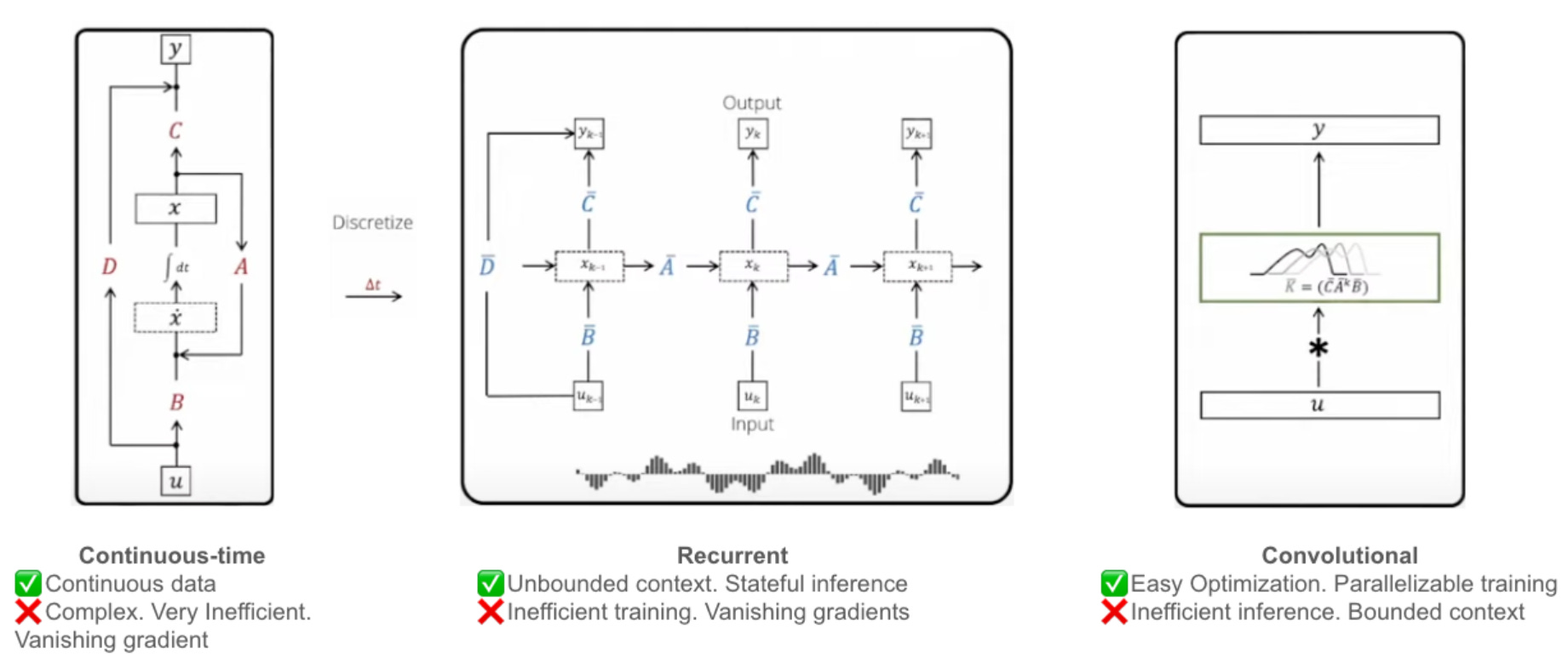
How it works: The authors combine Structured State Space Sequence (S4) models (an evolution of SSM introduced in another of their paper) along with the multi-layer perceptron of a Transformer into a single block: Mamba.
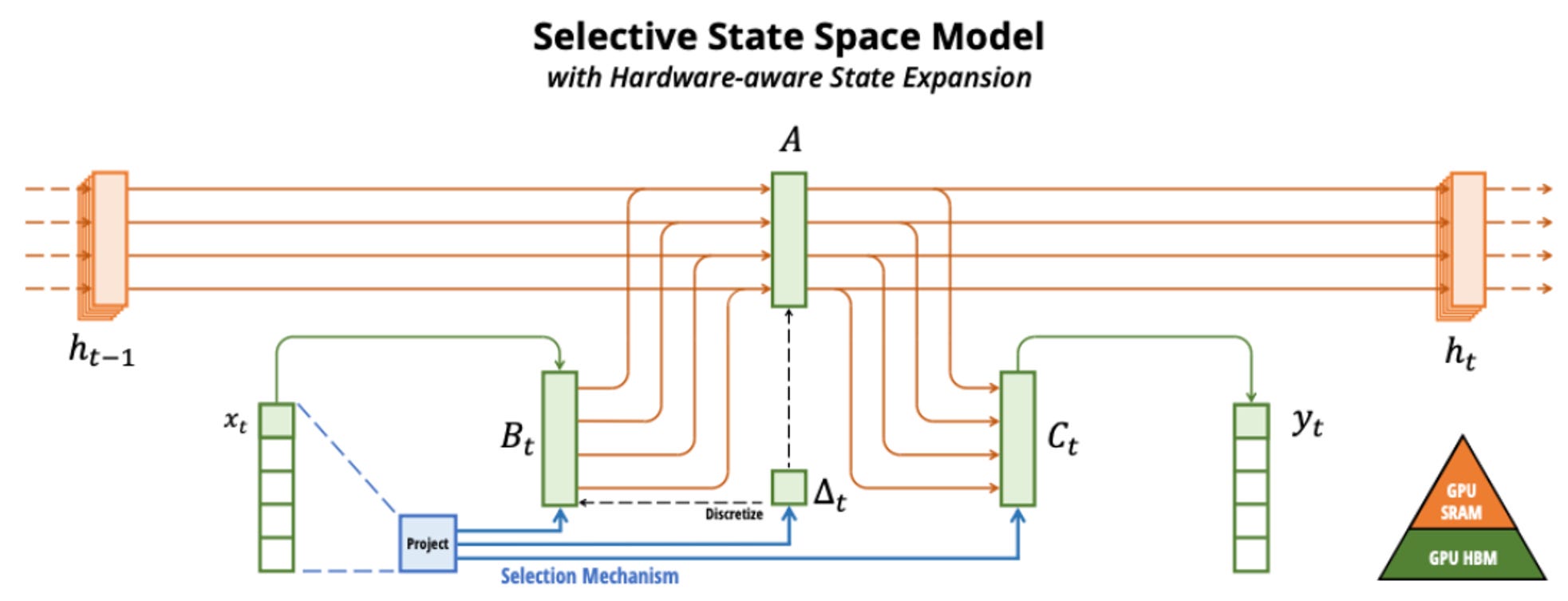
The most important part of the Mamba block is its selection mechanism, crucial in addressing how context is processed in sequence modeling. Attention networks maintain an explicit, uncompressed view of the entire context, allowing for selective focus on relevant parts. RNNs compress the full context into a hidden state, but their effectiveness can be hindered by how well this compression captures essential information. Meanwhile, State Space Models (SSMs) operate with fixed parameters over time, modeling the dynamics of hidden states and their observations consistently across sequences.
The authors propose to improve the selection mechanism by making it dependent on the input. This gives the architecture the ability to efficiently select data in an input-dependent manner (i.e., focus on or ignore particular inputs).
Results: Mamba was tested on a variety of use-cases (language modeling, DNA modeling, audio modeling and generation). Both accuracy and efficiency were evaluated. Mamba obtained very good results compared to open-source methods on both synthetic and real datasets for text and DNA but can be challenged by standard SSMs for continuous systems (audio/video).
Why it matters: SSMs and their derivatives are important alternatives to Transformer-based models. They could take an important place in the future landscape of foundation model architectures. The selection mechanism allows context-dependent reasoning that scales linearly with the sequence length. Use-cases requiring long context should benefit from this architecture.
Our takeaways: Following the evolution of SSMs is really interesting. However, understanding their previous work is required to fully comprehend the paper. We appreciated the detailed examples the authors provided, alongside the open-source code to reproduce the architecture. Also, as the evaluation was done with a small model, we wonder if the idea scales to 10B+ parameter models.
Reverse Favourite-Longshot Bias in Parimutuel Betting on Esports
What it is about: In 2019, researchers published a paper investigating gambling patterns on a betting website dedicated to the popular esports game Counter-Strike: Global Offensive (CS:GO). The authors aimed to define betting strategies and demonstrate market inefficiency by ****simulating significant positive profits.
How it works: The efficient market hypothesis claims that all relevant available information should be instantly reflected in stock prices (or betting odds in this context). A betting market could be considered to be inefficient if there is a strategy that allows bettors to consistently generate profit.
If a strategy proves to be profitable on an in-sample dataset, it indicates that the market was inefficient at a specific point in time. However, if the same strategy also yields profits on an out-of-sample dataset (different time interval), it suggests a more significant inefficiency, implying that this inefficiency is stable rather than temporary.
In this paper, the authors analyze betting market efficiency by examining the distribution of the share of underdog victories in matches.
What they found out: The study detected systematic underestimation of the underdogs. However, this finding does not guarantee positive profits for bettors. As a second step, the authors identified the reverse favorite-longshot bias, which is the phenomenon of overbetting on the favorites. They also established straightforward betting strategies focused on betting on underdogs, demonstrating that these strategies can outperform the market.
The market inefficiency investigated by the authors is not time-dependent. Testing on out-of-sample data confirmed the persistence of the reverse favorite-longshot bias and market inefficiency over time by showing the profitability of betting on underdogs.
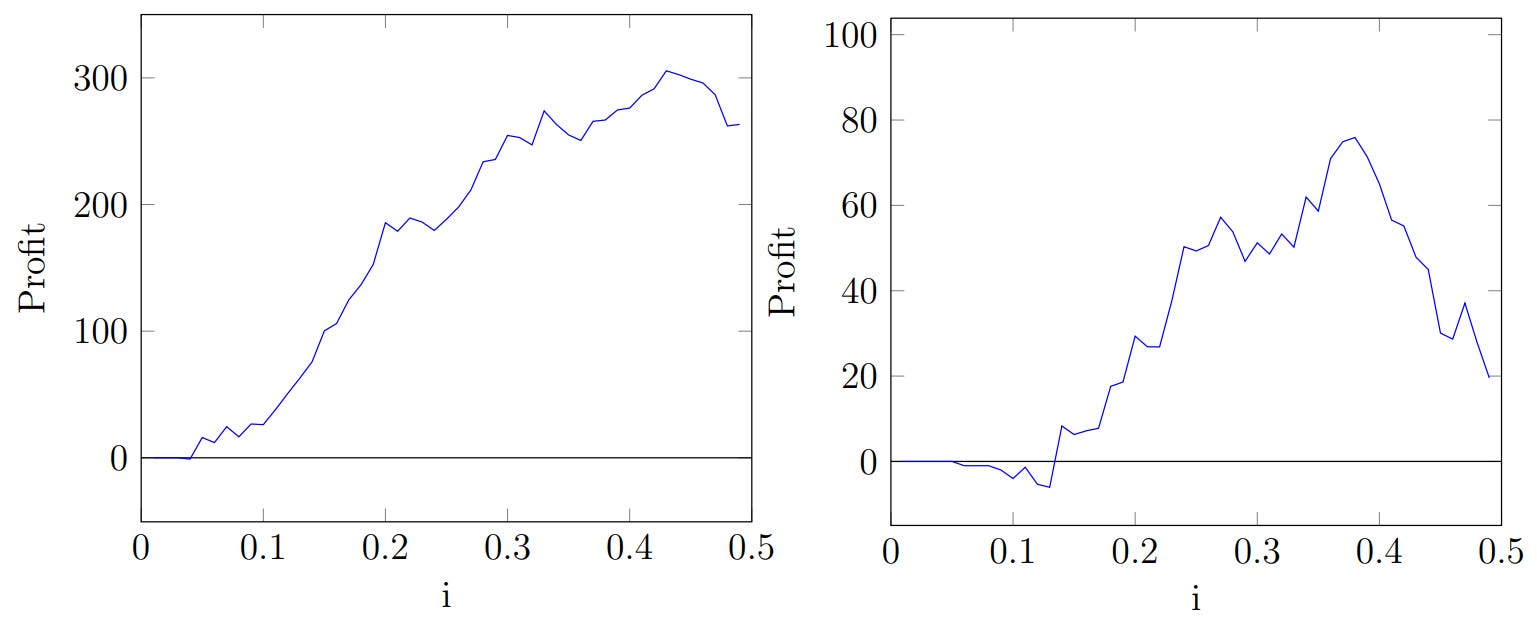
The authors also propose that more popular teams attract less experienced gamblers, contributing to market inefficiency. Additionally, the geographical location of teams influences market efficiency, with greater inefficiencies observed in matches involving European teams and teams coming from Post-Soviet countries.
Why it matters: The paper states that a reverse favorite-longshot bias exists in parimutuel betting markets, resulting in market inefficiency. Moreover, popular teams attract a higher number of inexperienced gamblers, contributing to a more pronounced reverse favorite-longshot bias in matches involving these teams.
Our takeaways: As an esports odds provider, we aim to have an efficient betting market where all participants are on equal footing and no one is consistently losing against others. This study is valuable as it raises awareness among bettors about potential biases they might have while betting.
 | A guest post by
|
 | A guest post by
|