
Next-gen Image Generation, Machine Learning at Uber, and Model Training Efficiency
PandaScore Research Insights #4



DALL-E 2 - Diverse and Realistic Text-conditional Image Generation
What it is about: Researchers from OpenAI have released in April 2022 a new text-conditional image generator, called DALL-E 2 (link to the paper). It can create artificial images from textual prompts and also edit them by adding or removing elements. Compared to their former DALL-E model, this one is more realistic, accurate, and has a higher resolution.
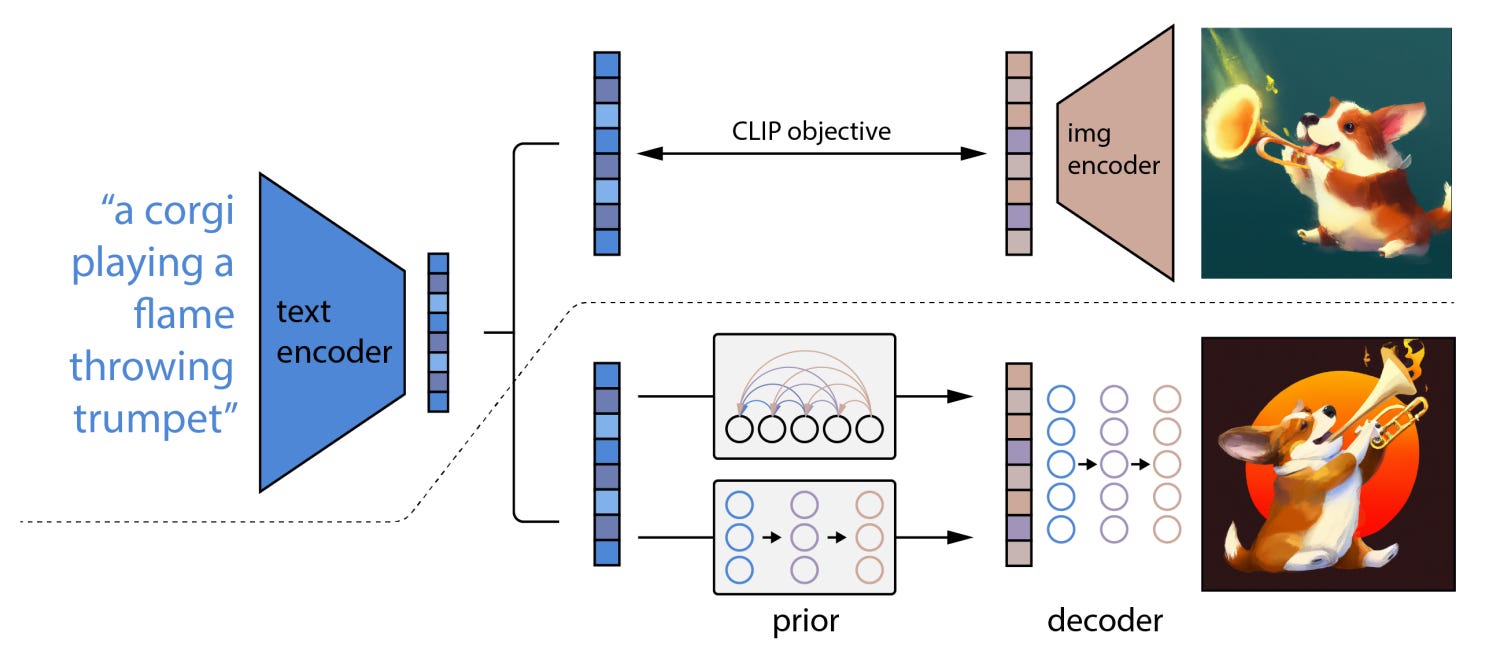
How it works: DALL-E 2 is based on CLIP and diffusion models, two recent advances in the field of computer vision:
CLIP is a model that extracts a joint hidden representation of images and captions. To do so, CLIP trains Transformers and Vision Transformers on image-caption pairs. With a contrastive loss, the model learns the similarity between images and captions.
Diffusion models are a type of generative models that learns to reconstruct, step by step, images from noise. Guidance can be added to the model to help it and control the end result. This is done by providing additional information to the model (e.g., the name of the class) during the reverse-diffusion step.
Here is how DALL-E 2 put them together:
First, the hidden representation of a textual prompt is extracted using CLIP.
Then a diffusion model generates the image embedding associated to the text embedding outputted by CLIP.
Another diffusion model decodes the created image embedding into an actual image. The model uses the caption embedding as guidance.
Finally, two other diffusion models up-sample the image into higher resolutions (1024x1024).

Why it matters: With DALL-E 2 and its components, AI seems to get representation of things that is closer to ours. It also sheds light into how advanced models see and understand our world. That being said, as the authors point out, the risks associated with artificial images getting more and more photo-realistic (e.g., deepfakes) should not be neglected. To limit the risks, the authors have made the model unable to generate violent, adult, or political images.
Our takeaways: While DALL-E 2 is really impressive, its only improvement over GLIDE (the authors former model) lies within the diversity of the created images. We feel that the key element of the DALL-E 2 pipeline (and of GLIDE as well) is the CLIP model, with its ability to conceptualize objects and ideas.
Scaling Machine Learning as a Service at Uber
What is it about: In this paper, written by Machine Learning engineers at Uber in 2016, a Machine Learning As a Service solution is presented. They address various scalability challenges: features computation, scoped models training and finally distributed model serving.
What they built: First, to compute and store features, they use a computation layer followed by a serving layer. The computation layer uses Samza to handle computations over streams. It also uses Apache Spark to perform processing of aggregates over large windows of data. The serving layer is composed of both online (Cassandra) and offline (Hive) feature store. While the online feature store is used for real-time predictions, the offline store is used for training and offline predictions.
Second, to limit the number of model instances to manage, they use a partitioned modeling approach. Basically, the method is to choose a generic model and define a hierarchy of data partitions (e.g. global, country, city). One instance of a model is trained per partition. In the case of a too small data partition, training on that partition is skipped altogether. At inference time, the model uses the most relevant child model: if a model wasn’t built for the partition, its parent model is used instead.
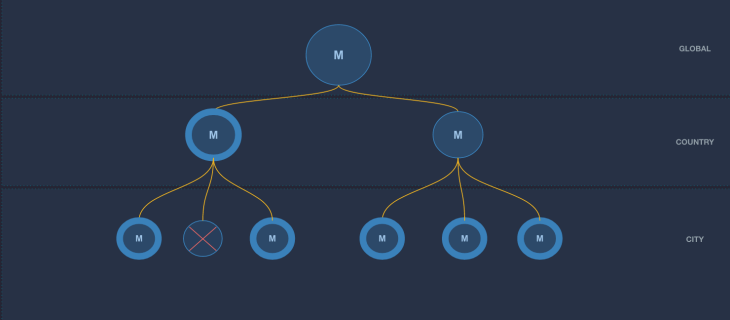
Third, they present the system responsible for loading and maintaining models and serving real-time predictions. They use a service-oriented approach, where each service manages a single hierarchical model. Each service periodically checks a model store for a new version, and eventually loads it.
Why it matters: The feature store architecture they propose solves:
the problems of serving long-life and short-life data at the same time;
the complexity of computing aggregates over long period of time;
data access issues: per entity for real-time or by bulk for training and offline predictions.
Handling model specialization using query context is not simple at really large scale. This hierarchical model approach allows a systemic and automated solution to this problem, both during training and inference.
Finally, the architecture they describe for model serving introduces an abstraction between serving and deployment. This decoupling is an innovation in terms of software engineering and team organization. It enables System engineers and Data Scientists to work asynchronously, while offering high monitoring capabilities.
Our takeaways: While their feature store doesn't seem that of a novelty (it really resembles a Λ-architecture), it provides an industry-proven implementation that works at large scale. The hierarchical model approach is really interesting for automated training and serving, but appears to be usable only for simple, generic Machine Learning models (e.g. linear regression, XGBoost). With this kind of models, most of the complexity is handed over to feature engineering and not to the models themselves.
Training Only on Data Worth Training on
What it is about: The training process for neural networks with very large datasets faces a lot of challenges. This paper, published in 2022, focuses on eliminating wasted computation time during training with redundant or noisy data points.
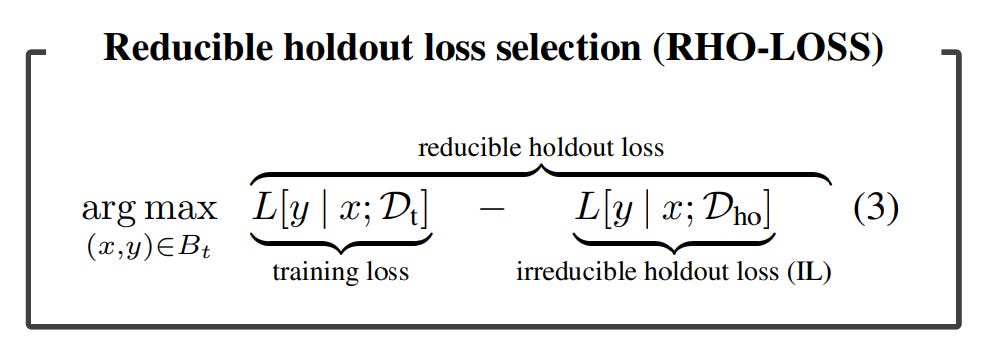
How it works: The proposed methodology follows an online batch selection framework. After doing the forward pass for the entire training batch, only a subset of data points are selected for the backward pass.
Instead of working on the training set to identify this set of data points, they use another dataset they call the holdout set. This dataset is much smaller than the training set and is used to train another, smaller, model. The relevant data points are selected during the training of the main model as the points that have the biggest RHO-LOSS. This loss is computed as the difference between the training loss and the loss on the holdout set. The selected data points are the points that the smaller model was able to learn (low holdout loss) but the current model has not learnt yet (high training loss).
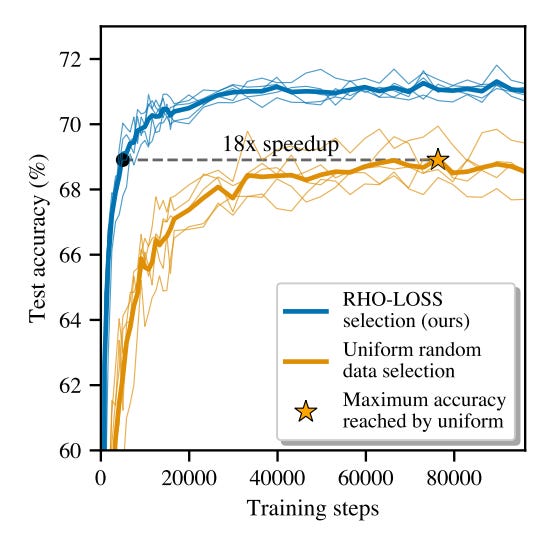
Results: Experiments have been conducted with standard neural network architectures on several datasets, both computer vision and NLP-based. For all of the experiments, this approach resulted in significant reduction in epochs needed for convergence. Sometimes it also led to an increase in accuracy.
Why it matters: As datasets become bigger, which is needed to fuel bigger models, the need to filter out the most relevant data to train on, becomes important. The bigger the dataset, the higher the chance of having bad (e.g., redundant or outlier) data points. Even if a well-designed model could theoretically learn to ignore these data points, processing power is still wasted in the end.
Our takeaways: Despite the significance of the results, this paper is only highlighting the cases were the dataset size is so large that it creates bottlenecks, even when using multiple machines. At the time of writing, this an issue in very few domains, but will definitely find its way in others in the near future. Also, this work could be used outside of training as a dataset analysis tool. It could help better understand the composition of datasets (redundancy in the data, noise, etc.).
 | A guest post by
|
 | A guest post by
|