

Insecure Code with LLM, bets losing more than expected, and LeCun's path towards autonomous machine intelligence
Insecure Code with LLM, bets losing more than expected, and LeCun's path towards autonomous machine intelligence
PandaScore Research Insights #11




Do Users Write More Insecure Code with AI Assistants?
What it is about: This paper from December 2022, authored by researchers from Stanford University, investigates the security risks associated with the use of AI code assistants, such as Github Copilot, which are built on large models pre-trained on publicly available code. This study measures correctness of the answers, security levels, and provides a trust-in-the-model analysis to gauge how much people trust model answers in relation to their own knowledge in the subject.
How it works: The study involved a comprehensive user study with 47 participants, comprising 31 undergraduates, 9 graduates, and 7 professionals, each with varying coding knowledge. They were assigned 5 different security-related programming tasks spanning 3 different programming languages (Python, JavaScript, and C). The study aimed to understand the extent to which AI assistants lead users to write insecure code and how users inadvertently cause security mistakes by interacting with AI systems.
Results: The paper discusses two main topics:
Security and correctness: on most questions, people are more likely to write insecure code when using an AI assistant. Surprisingly, even the proportion of correct code was higher in the control group.

Trust in the model: people tend to trust AI assistant answers more than they should, even when the answers are incorrect. Interestingly, the less skilled people are in the tasks, the more they tend to trust the AI. Furthermore, the study notes that people who challenge the AI assistant's answers, rephrase problems, adjust temperature settings, etc., tend to receive better answers.
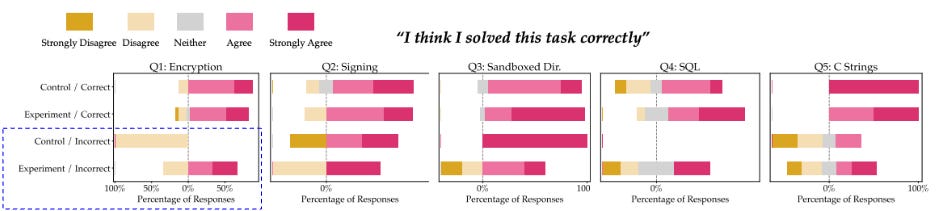
Results on model trust.

Why it matters: As the use of AI code assistants becomes increasingly popular, it is crucial to understand their limitations and assess the extent to which we can trust them. Learning how to use such tools effectively will be crucial for developers in the near future.
Our takeaways: While many people use these tools today, the study reaffirms that we cannot blindly trust AI. Challenging the AI, rephrasing problems, and using prompt design strategies can be highly effective and result in significantly better outcomes. With AI assistants, developers are shifting their skills more towards testing code and detecting issues. This will undoubtedly impact our recruitment process, as every developer will now face this new challenge.
As a limitation of this study, it should be noted that the large language model (LLM) used was generic and not specifically trained for security.
Calculating the bookmaker’s margin: bets lose more than expected
What it is about: This year, a paper was published by researchers from University College Dublin, revealing that average realized loss rates on bets consistently exceed predictions made by the conventional overround calculation.
How it works: The well-established overround formula, calculated by summing inverses of the decimal odds, is founded on the assumption that the betting market operates efficiently, maintaining consistent expected profit margins for each event outcome. However, various studies have pointed to the existence of a favorite-longshot bias in betting markets. This bias indicates that losses incurred from betting on underdog outcomes are more significant compared to those from betting on favorites.
The overround formula, computed by summing inverses of decimal betting odds:
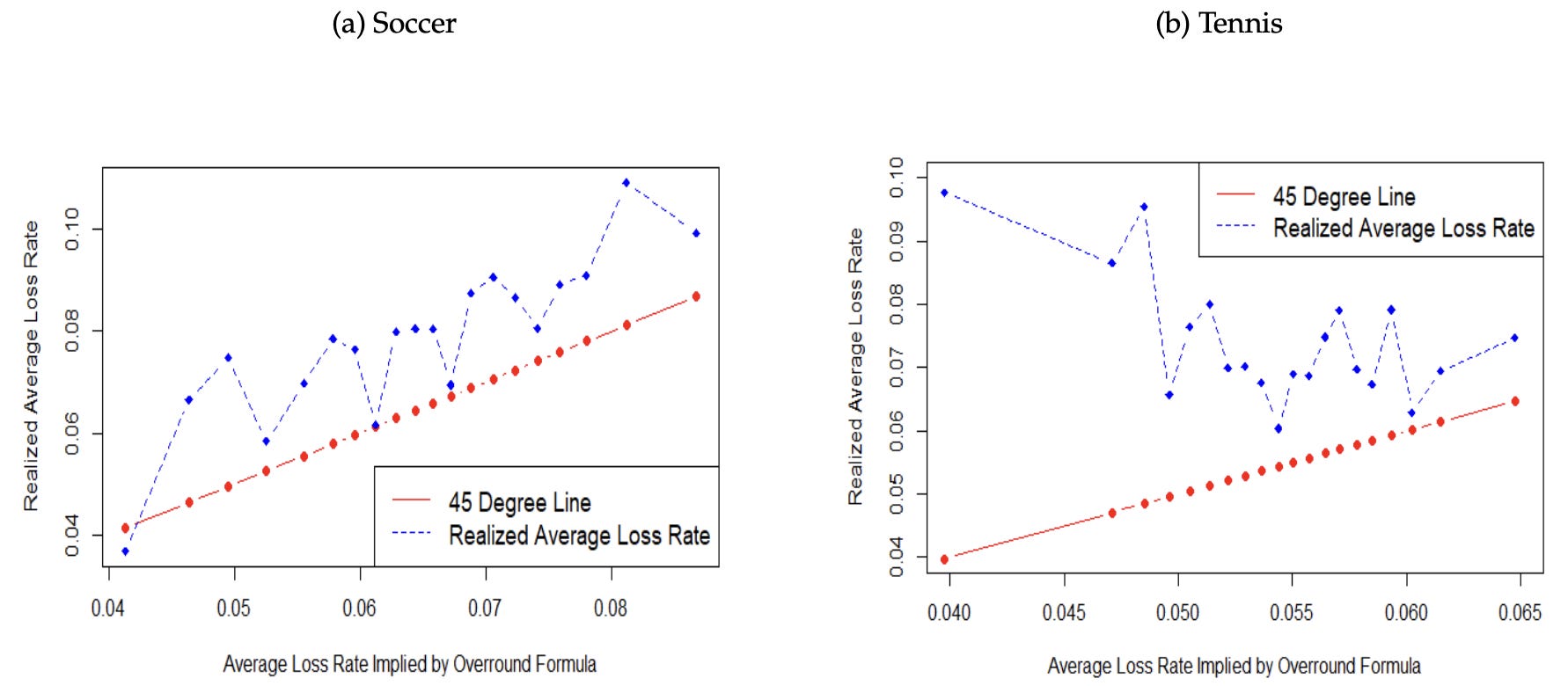
While this bias is widely acknowledged, its implications within the well-known overround formula have not been fully explored. In this paper, the authors demonstrate that if bookmakers sustain higher profit margins for bets with lower chances of winning, the average loss rate for all wagers will surpass what is suggested by the overround formula. They also provide concrete examples from soccer and tennis betting to illustrate this phenomenon.
Results: The authors demonstrated that in scenarios where bookmakers set higher profit margins for bets associated with lower probabilities of winning, which is a common practice in various betting markets, such as those observed in soccer and tennis, the overround formula fails to accurately calculate the average loss rates across all wagers.
In the example discussed in the paper, the actual average loss rates are higher than predictions, with soccer betting experiencing a one-fifth increase and tennis betting seeing a forty percent rise in average loss rates compared to what was implied by the overround formula.
Why it matters: Numerous guides are available to help bettors in understanding how the market operates. The fundamental aspect is the use of the overround formula to ascertain the bookmaker's profit margin, thereby estimating the expected losses for bettors.
The authors suggest that individuals interested in sports betting should be aware that, on average, they are likely to lose more on the bets offered by bookmakers than indicated by the widely recommended overround calculation.
Our takeaways: At PandaScore, we aim to promote transparency and advocate for informed decision-making in esports betting. By highlighting real risks and potential returns, this academic work encourages responsible betting practices. We fully support this initiative as it contributes to a safer betting environment.
Yann LeCun View on How to Train Autonomous Agents
What it is about: In this pioneering paper released this year (not peer-reviewed), Yann LeCun explores the central question of how machines could learn as efficiently as humans. Indeed, while a young adult can learn how to drive in just a few hours, a machine has to be trained with a vast amount of data for days.
How it (would) works: The author envisions a family of models composed of six modules: configurator, perception, world model, cost, actor, and short-term memory. The world model module is of particular emphasis in the paper, with LeCun suggesting that it should be trained using self-supervised learning. The goal of this model is to predict future states of the world using a Joint Embedding Predictive Architecture (JEPA). JEPA is an energy-based model (EBM) that identifies dependencies between two inputs, enabling predictive capabilities in representation space. In deep learning, an EBM assigns a numerical "energy" value to different input data to determine which ones are more probable or preferred.

Why it matters: The pursuit of machines learning with human-like efficiency stands as a monumental challenge. LeCun's work not only addresses theoretical gaps but also offers potential pathways for real-world applications, especially considering his influential standing in the AI community. His approach contrasts with the dominant trend of Large Language Models (LLMs), which are primarily generative. While LLMs aim to produce content based on extensive training data, LeCun's models aim at genuinely understanding the world, making learning more adaptive and efficient. This distinction revitalizes the AI conversation, emphasizing the importance of machines that can intuitively learn and reason, rather than just generate outputs based on vast amounts of training data.
Our takeaways: As a forward-looking AI company, we remain deeply invested in staying abreast of all research developments, especially those that introduce novel paradigms in the AI landscape. Yann LeCun's work brings fresh perspectives to the table, challenging and expanding our understanding of machine intelligence. We took particular note of the Joint Embedding Predictive Architecture (JEPA) presented in this paper. Furthermore, the recent introduction of an iteration on this model, known as i-JEPA, has piqued our interest. Given our specialized focus on using computer vision to extract esports data, the potentials of i-JEPA and its underlying principles could offer innovative ways to enhance our methodologies and output.
 | A guest post by
|
 | A guest post by
|