

Esports team composition, uncertainty and truth discovery
Esports team composition, uncertainty and truth discovery
PandaScore Research Insights #1



This post is the first one of PandaScore’s Research Insights newsletter!
It has been more than 4 years that we have been running a weekly Journal Club in the data science team of PandaScore. We are covering many different topics such as computer vision, prediction, and data science for esports.
Starting today, we will share with the community on a regular basis our key takeaways from the research papers we study. Enjoy the read and make sure to subscribe!
Optimal LoL team composition
What it is about: In 2019, a team of Brazilian researchers have published a paper presenting a method to generate League of Legends team compositions based on Genetic Algorithm.
How it works: First, the authors started to define three different battle strategies a team composition must fall into: a team fight strategy, a hard engage strategy or a poke/siege strategy. Then, they defined a fitness function for each of the strategies. Given the strategy, it aims at evaluating the goodness of a team composition. The fitness functions are using the champions base characteristics, such as attack damage, movement speed, hp or attack range. These fitness functions were optimized separately by Genetic Algorithm. In the optimization, the team composition was constrained to have at least a carry and a support. Results showed that all the models converged for all the battle strategies. At the end, they provide believable team compositions (see picture below).
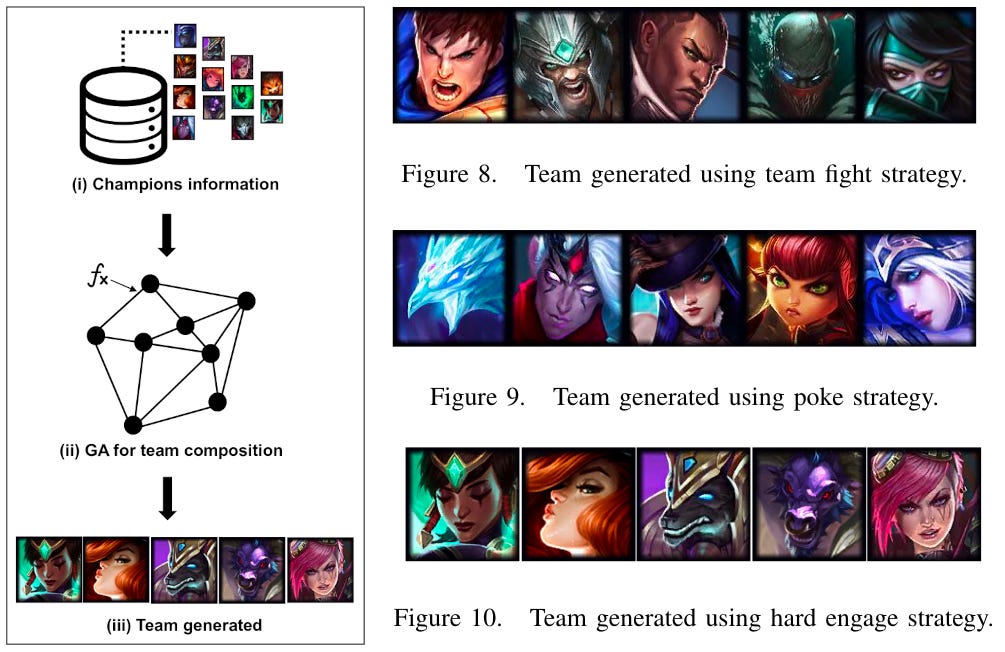
Why it matters: Team composition in general is a deciding factor in the winning of a MOBA game. Coaches could use such algorithm during the drafting phase to help them come up with better team compositions. Consequently, other researchers have explored various ways to this problem, such as building an expert system with the MinMax algorithm, or through a hero recommendation engine in Dota 2.
Our takeaways: It was refreshing to see an expert, non-data, approach to such a problem. We were quite amazed by how they managed to get team compositions that were making sense using only the champions base statistics. These results could be further improved by adding more defining elements of a champion such as its role (top, mid, ...), class (juggernaut, marksman, ...) or abilities. That being said, we would have liked an analysis of the potential viability of the generated team compositions through data. What kind of team compositions pros tend to use? Are there other battle strategies? Which battle strategy is winning more?
Truth Discovery with Multiple Conflicting Information Providers on the Web
What it is about: In 2008, researchers from UIUC describe an original problem, called truth discovery, which studies how to find true facts from a large amount of conflicting information. They introduce an algorithm that utilizes the relationships between sources and their information to successfully find true facts better than any single source of information. They apply it to the domain of web sites listings of book authors.
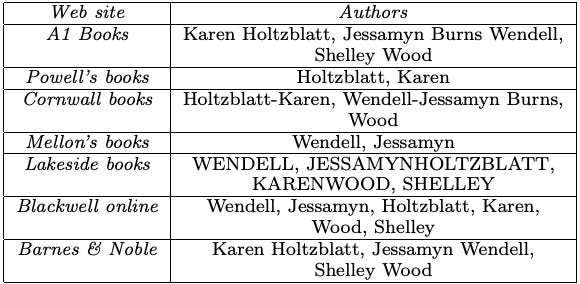
How it works: There are web sites (w) that provide facts (f) about objects (o). For example, the website “Powell’s books” (w) states that the book “Rapid Contextual Design” (o) has the authors “Holtzblatt, Karen” (f). We don’t have access to the ground truth. Each web site is given a trustworthiness score and each fact is given a confidence score. Both scores are scalars and uniformly initialized.
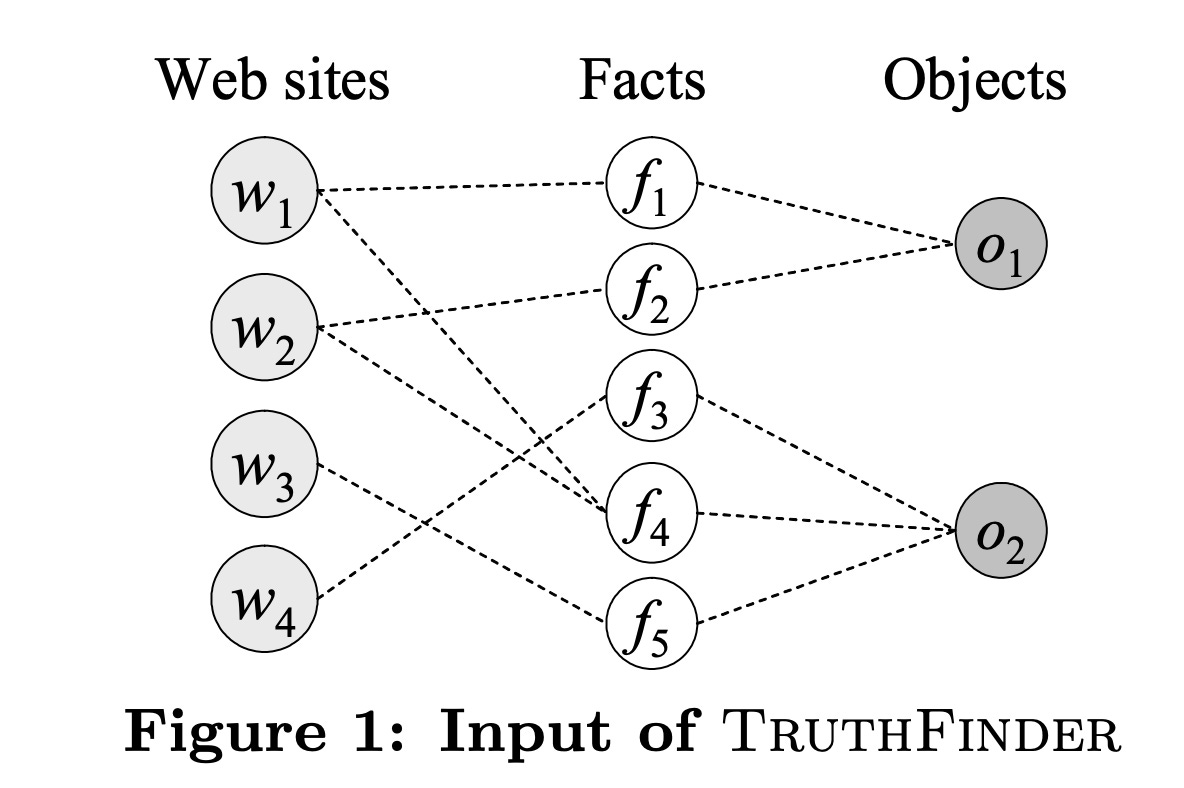
In the first step, the authors use the assumption that a web site is trustworthy if it provides many facts with high confidence to compute the trustworthiness score of each web site. Then, they use the assumption that a fact has high confidence if it is provided by many trustworthy web sites to compute the confidence of each fact. These steps are repeated iteratively until convergence of both the trustworthiness and the confidence. The paper also includes additional subtleties, notably handling dependency between web sites (some web sites copy the content of others) as well as dependency between facts (facts that are very close should have similar confidence).
Why it matters: Increasingly available datasets make it harder to come up with a single source of truth. It also makes labeling the data exceedingly expensive. This unsupervised method is a fast and efficient way to outperform the naive baseline of majority voting. You can consider it as an ensemble method with priors (assumptions) on the predictors.
Our takeaways: The algorithm is fast, easy to implement and offer a compelling alternative to labeling huge datasets. However, the assumptions are very strong, and they may not be relevant for all problems. Also, trustworthiness and confidence scores are single scalars, which may fail to capture the complexity of the problem.
Overcoming Limitations of Mixture Density Networks
What it is about: The authors of this paper (University of Freiburg, 2020) suggest a new framework for multimodal future prediction using Mixture Density Networks (MDN). This paper aims at predicting better the uncertainty and multimodality of such systems using deep learning.
How it works: The backbone of the model used in this paper is a MDN. Such models output, given the inputs, the parameters of several parametric distributions forming a mixture density distribution.

On challenging tasks such as forecasting the future location of a car given past images, MDN showed some numerical instability and mode collapsing. The authors showed that a new model that splits the work in two is improving the forecasts significantly. First, “hypotheses”, which are plausible output samples, are generated. Then, the mixture density distributions are computed from these hypotheses.
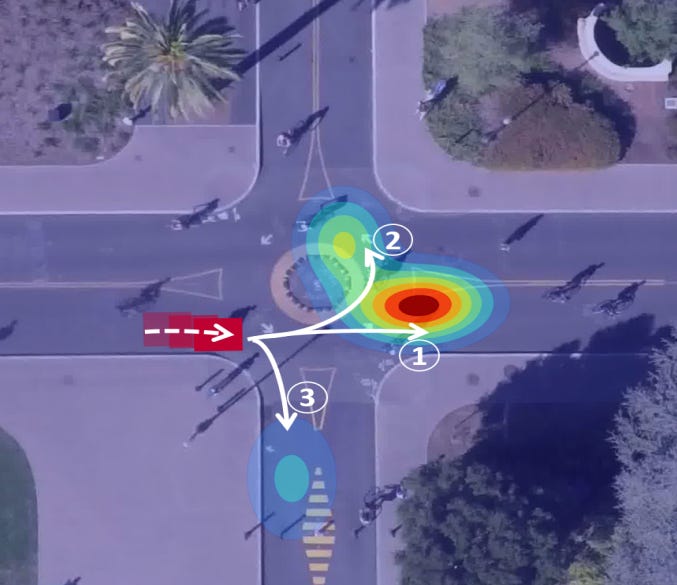
Why it matters: Predicting the future of a given non-deterministic system given its past states is crucial in many industries such as autonomous driving, biology or betting. For instance, it is critical for autonomous cars to forecast all possible “modes”, even unlikely ones. As you can imagine, even a 1% chance for a pedestrian to cross the road at the very last minute should be taken into account by the car.
Our takeaways: At PandaScore, we are really interested in all scientific advances regarding uncertainty modeling. Ultimately, a League of Legends game is nothing else than a system with a lot of randomness that can take different paths before reaching an end. Different modes could be taken into account such as stomps, tight games with a lot of team fights, or “boring” games finishing with a single team fight around the Baron Nashor. It is by accurately modeling the uncertainty that we can offer the best odds to our customers.
 | A guest post by
|
 | A guest post by
|